Тема: Построение характеристического вектора клик веб-графа и его применение для анализа структуры сайтов
Закажите новую по вашим требованиям
Представленный материал является образцом учебного исследования, примером структуры и содержания учебного исследования по заявленной теме. Размещён исключительно в информационных и ознакомительных целях.
Workspay.ru оказывает информационные услуги по сбору, обработке и структурированию материалов в соответствии с требованиями заказчика.
Размещение материала не означает публикацию произведения впервые и не предполагает передачу исключительных авторских прав третьим лицам.
Материал не предназначен для дословной сдачи в образовательные организации и требует самостоятельной переработки с соблюдением законодательства Российской Федерации об авторском праве и принципов академической добросовестности.
Авторские права на исходные материалы принадлежат их законным правообладателям. В случае возникновения вопросов, связанных с размещённым материалом, просим направить обращение через форму обратной связи.
📋 Содержание
Постановка задачи 6
Глава 1. Характеристический вектор клик веб-графа 7
Глава 2. Программа сканирования сайта для построения его веб-графа 9
Глава 3. Программа поиска клик 11
Глава 4. Эксперименты с сайтами СПбГУ 16
4.1. Сканирование сайтов 16
4.2. Построение векторов клик веб-графа 19
Глава 5. Кластерный анализ 23
5.1. Общие сведения 23
5.2. Кластеризация результатов работы программы
построения векторов клик веб-графа 26
Выводы 28
Заключение 29
Список литературы 30
📖 Введение
Для его построения необходим список веб-сайтов, которые будут выступать в качестве множества вершин, и список гиперссылок между этими сайтами, которые будут составлять множество дуг веб-графа. Такой граф будет иметь ребра-петли, и он будет ориентированным.
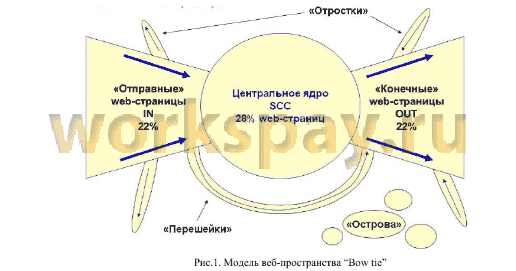
Крупное исследование веба с применением веб-графа в 1999 году произвел Андрей Бредер вместе с коллегами. Исследовав более 200млн. страниц ученые построили веб-граф и, проанализировав его, пришли к выводу, что все страницы можно разделить на 5 множеств:
1. Центральное ядро - тесно связанные страницы, то есть с любой страницы этого множества можно перейти на любую другую страницу этого множества по конечному числу гиперссылок.
2. “Отправные” web-страницы - на этих страницах содержатся гиперссылки, ведущие в центральное ядро, но из ядра к ним попасть невозможно.
3. “Конечные” web-страницы - страницы, обратные к отправным, к ним можно попасть из ядра, но в ядро с них попасть невозможно.
4. “Отростки”, “перешейки” - полностью изолированные от центрального ядра страницы.
5. “Острова” (или hidden web) - страницы, на которые не существует гиперссылок. Попасть на них можно только зная их адрес.
Однако, в современном мире количество веб-ресурсов становится все больше и больше, количество сайтов стремительно увеличивается, соответственно растет и количество гиперссылок между ними. Так же растет количество страниц, входящих в множество “островов”. Поэтому исследование веба в целом было выполнимо только на начальных этапах его развития, в наше же время исследования представляются возможными лишь на сравнительно небольших фрагментах веб-пространства.
В качестве таких фрагментов можно рассматривать веб-сайты[21. Эти фрагменты так же хорошо описываются веб-графом и, как и само вебпространство, имеют довольно сложную структуру. Например, на сайте Оксфордского университета Google проиндексировал около 8 миллионов страниц, а на сайте Г арвардского университета около 6 миллионов страниц.
В отличие от веб-графа всего веба, веб-граф сайта имеет определенную точку входа - главную страницу сайта, ее можно идентифицировать по доменному имени. Эту страницу так же называют индексной страницей из-за того, что поисковые системы начинают индексирование веб-сайта именно с нее.
Это значит, что у веб-графа сайта будет явная начальная вершина. Соответственно в таком графе можно выделить уровневую структуру. У главной страницы сайта уровень 0, у каждой страницы, ссылка на которую найдена на главной странице, уровень 1 и так далее. То есть уровень страницы определяется минимальным количеством гиперссылок от главной страницы до искомой.
Кроме того, веб-граф сайта будет являться как минимум слабо- связным[4]. В контексте ориентированного графа это означает, что при замене ориентированных ребер (дуг) на неориентированные, будет существовать как минимум один путь из любой вершины в любую другу вершину графа.
Веб-графы некоторых сайтов (обычно это сайты с небольшим количеством страниц) могут быть не только слабо-связными, а еще и сильносвязными. То есть из любой вершины такого графа существует хотя бы один ориентированный путь в любую другую вершину...
✅ Заключение
Все задачи, поставленные в ходе исследования, были решены.
📕 Список литературы
🖼 Скриншоты