Тема: ПОСТРОЕНИЕ И РЕАЛИЗАЦИЯ НАБОРА ИГРОВЫХ СТРАТЕГИЙ НА ОСНОВЕ ОБУЧЕНИЯ НЕЙРОННЫХ СЕТЕЙ С ПОДКРЕПЛЕНИЕМ
Закажите новую по вашим требованиям
Представленный материал является образцом учебного исследования, примером структуры и содержания учебного исследования по заявленной теме. Размещён исключительно в информационных и ознакомительных целях.
Workspay.ru оказывает информационные услуги по сбору, обработке и структурированию материалов в соответствии с требованиями заказчика.
Размещение материала не означает публикацию произведения впервые и не предполагает передачу исключительных авторских прав третьим лицам.
Материал не предназначен для дословной сдачи в образовательные организации и требует самостоятельной переработки с соблюдением законодательства Российской Федерации об авторском праве и принципов академической добросовестности.
Авторские права на исходные материалы принадлежат их законным правообладателям. В случае возникновения вопросов, связанных с размещённым материалом, просим направить обращение через форму обратной связи.
📋 Содержание
сетей с подкреплением 7
1.1. Примеры построения искусственного интеллекта в
настольных играх. Сравнение классического и нейросетевого подходов 7
1.2 Примеры игровых моделей и подходов для реализации среды
для обучения нейронных сетей 19
2. Проектирование игровой модели на примере игры крестики
нолики пят в ряд 23
2.1. Логика реализации игры 23
2.2. Параметры оценочной функции 27
2.3. Использование альфа-бета отсечения для оптимизации
вычислений 30
3. Примеры из сыгранных партий и пояснения 32
3.1. Соревнование между агентами и человеком 32
3.2. Перспективные направления дальнейшего развития проекта... 34
Заключение 36
Библиографический список 38
Приложение 39
📖 Введение
Тема выпускной работы: «Построение и реализация набора игровых стратегий на основе обучения нейронных сетей с подкреплением».
Цель работы - реализация двух подходов построения нейросетей для генерации неочевидных для человека стратегии на примере одной игры (игра крестики-нолики пять в ряд).
Предмет исследования - создание агентов на основе обучения нейронных сетей с подкреплением.
Объект исследования - способы построения целевой и оценочной функций в играх, а также влияние изменений правил игры на эти функции.
В результате исследования решены следующие задачи: построена целевые функции для обучения нейросетевых агентов, разработана среда взаимодействия нейросетевых агентов, проведено обучение нейросетей, построен GUI игры, проанализированы результаты обучения соревновательным путём.
Объем работы 41 страница, количество рисунков - 17, таблиц - 7, приложений - 1, 15 использованных источников литературы.
Ключевые слова: обучение с подкреплением, нейронные сети, целевая функция, оценочная функция, среда взаимодействия агентов.
На сегодняшний день методы машинного обучения с подкреплением являются одним из самых перспективных направлений в области искусственного интеллекта. Типичным примером подобного способа компьютерного самообучения являются системы поддержки принятия решений в реальном времени.
Одна из основных идей подобных систем состоит в том, что изначально агенты обучения не имеют представления о правилах, действующих в той среде, в которой существует агент.
На первом этапе необходимо создать саму среду, в которой будут взаимодействовать агенты. На втором этапе создателю системы необходимо задать целевую функцию для агента, которую необходимо максимизировать (или минимизировать).
На третьем этапе необходимо создать события, за которые мы будем награждать искусственный интеллект и за которые мы будем его наказывать и запускаем первые эпохи обучения. В ходе процесса обучения агенты, достигшие наилучших результатов, будут выбраны в качестве основы для следующего поколения обучения.
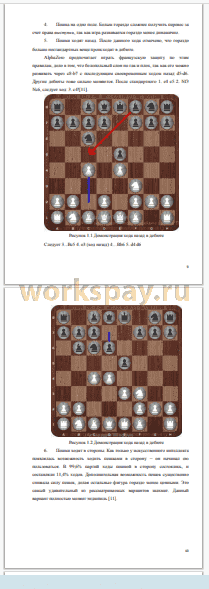
На данном этапе происходят наиболее важные события с точки зрения анализа последующих результатов. Заранее невозможно предсказать результат обучения с подкреплением ввиду случайности принимаемых решений на ранних этапах обучения. Вероятен следующий исход: на раннем этапе стратегия, наиболее слабая в долгосрочной перспективе, приносит наиболее высокий выигрыш на раннем этапе игры, искусственный интеллект видит, что у данной стратегии наиболее высокий выигрыш, и отбрасывает остальные стратегии, и дальнейшая эволюция обучения происходит на основе заведомо наиболее слабейшей стратегии в долгосрочной перспективе. Возможные способы решения данной проблемы заключаются в изменении правил игры (как отдельных количественно для отдельных параметров, так и добавление новых параметров, создание новых ключевых событий в игре, переоценка важности целевой функции, применение комбинированных алгоритмов (вроде альфа-бета отсечения)).
За последнее десятилетие обучения с подкреплением достигло ощутимого прогресса, данная область успела пройти путь от первых робких попыток, до победы над человеком в таких играх как го, хотя классическое программирование исключало подобных исход. На сегодняшний день уже возникла острая потребность в специалистах, способных создавать модели обучения с подкреплением и анализировать результаты, полученные в ходе обучения.
Сложно переоценить, насколько важным является анализ самого процесса обучения агентов - неэффективно просто создать среду, задать правила и целевую функцию, и запустить процесс обучения в надежде, что искусственный интеллект сам определит оптимальную стратегию. Необходимо непрерывно корректировать процесс его обучения для исключения заведомо неэффективных стратегий методами, описанными выше.
Целью данной работы являет реализация двух подходов построения нейросетей для генерации неочевидных для человека стратегии на примере одной игры (игра крестики-нолики пять в ряд)
Но, суть данной работы заключается в создании нейронных сетей, которые будет генерировать неочевидные игровые стратегии.
На основе реализации двух подходов в обучении нейросетевых агентов можно сравнить их результаты и выявить наилучший. В процессе игры с человеком можно запросить подсказку от любого из двух агентов для указания на сильнейшее решение.
Для реализации цели следует решить следующие задачи:
1. Построить целевые функции для обучения нейросетевых агентов
2. Разработать среду взаимодействия нейросетевых агентов.
3. Провести обучение нейросетей
4. Построить GUI игры
5. Проанализировать результаты обучения соревновательным путём
6. Определить и зафиксировать неочевидные игровые стратегии (и попытаться найти им обоснование)
Объект исследования - решение задач на основе обучения с подкреплением
Предметом исследования является применение нейронных сетей с подкреплением для реализации игровых стратегии на примере игры «крестики нолики».
Научная новизна. В исследовании предложен и продемонстрирован подход построения целевой функции игры с учетом возможности получений «награды» за очередной «безопасный» ход. Максимальный выигрыш ИИ (искусственный интеллект) получает не только от победы в партии, но и за очередной «безопасный» ход в выигранной позиции.
Практическая значимость. Данное исследование актуализирует проблематику применения нейронных сетей для поиска неочевидных игровых стратегий. Такие неочевидные игровые стратегии имеют достаточно широкую область практического применения от простейших настольных игр до биржевых торговых агентов.
✅ Заключение
Первой ступенью в исследованиях нейронных сетей в силу своей простоты были некооперативные игры. Современная теория игр разработала довольно широкий математический аппарат для таких игр. Однако, экономическое взаимодействие субъектов больше похоже на игры кооперативные. Для таких игр математический аппарат разработан гораздо меньше. Обучение в мультиагентной среде - следующий перспективный шаг в развитии искусственного интеллекта. Анализ взаимодействия агентов может позволить выявить методы и стратегии, ранее скрытые от исследователей в силу своей неочевидности. В реальной ситуации на рынке агенту может как противостоять другой агент, так и играть с ним в команде. Поэтому агент должен уметь в равной степени как эффективно взаимодействовать с дружественными агентами, так и противостоять оппонирующим агентам не только в одиночку, но и используя особенности, преимущества каждого члена своей команды, а также учитывать их слабые стороны.
В ходе обучения двух агентов выявлено преимущество подхода обучения, использующего игровые особенности конкретной игры (паттерны поведения), однако двух тысяч эпох обучения было явно недостаточно для соперничества с человеком на равных. Но в машинном обучении такое количество эпох является довольно невысоким показателем, и проигрыш сети не был разгромным. Существует несколько возможных подходов к решению данной проблемы: нарастить количество эпох обучения до 10000, или же попытаться ввести дополнительные параметры (плотность расстановки собственных клеток, более полное раскрытие опасных паттернов соперника). Также в ходе обучения выявлены случаи необычного поведения агента, основанного на паттернах. В некоторых ситуациях он имел форсированный выигрыш в один ход, но просчитывая свою целевую функцию в глубину, при нахождении того, что соперник не может выиграть его раньше, старался построить новый паттерн, продолжая партию, и получая дополнительный бонус к целевой функции за совершенный ход и за построение паттерна. Данная особенность при применении к другим играм (как мультиагентным, так и с одним агентом) сможет помочь выявить скрытые ранее в силу своей неочевидности стратегии.
Однако, без оптимизации время вычислений неоправданно затягивается, а мощность современных компьютеров не позволяет рассчитывать крупные деревья игр до конца в краткие сроки. Однако, даже если бы они могли рассчитывать их до конца - это не стало бы поводом к отказу от оптимизации - снижение потенциального количества пользователей из-за высоких системных требований не шло на пользу ни одному из программных продуктов.
📕 Список литературы
🖼 Скриншоты