Введение 4
1. Постановка и анализ задачи 6
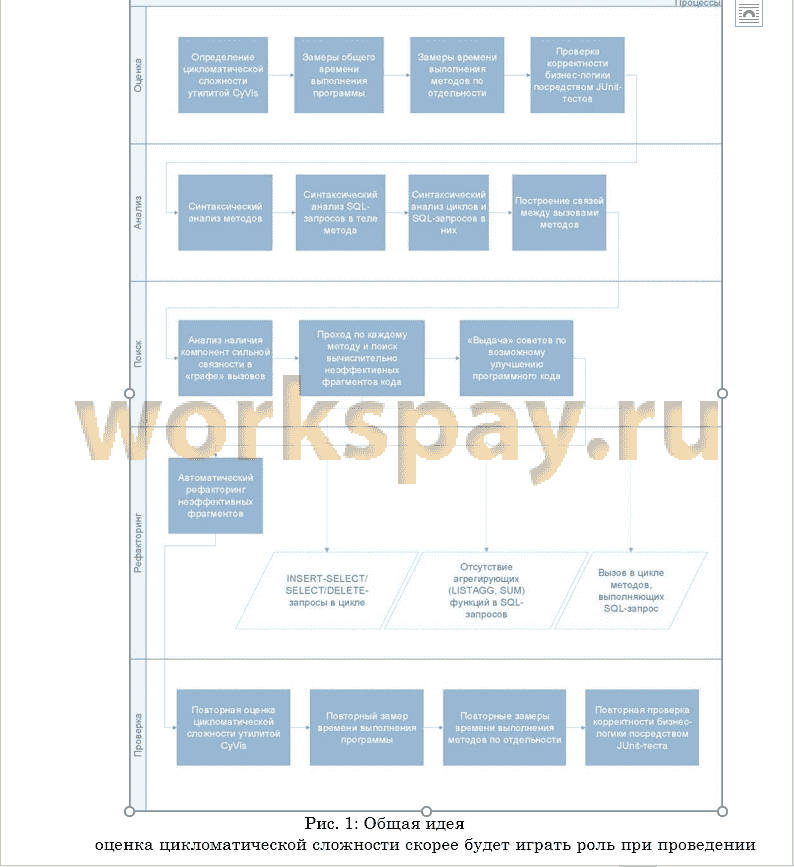
1.1. Общая идея 6
1.2. Метрики и оценка качества 7
1.3. Разбор исходного кода 9
1.4. Синтаксический анализ методов 11
1.5. Синтаксичекий анализ SQL-запросов 13
1.6. Синтаксический анализ циклов 14
1.7. Анализ «графа вызовов» методов 15
2. Реализация трансформации 16
2.1. Поиск и рефакторинг неэффективных фрагментов про-граммного кода 16
2.1.1. Типичные запросы в цикле 16
2.1.2. Отсутствие агрегирующих функций 20
2.1.3. Вызов в цикле методов, содержащих SQL-запрос . 22
3. Эксперименты 26
4. Оптимизация взаимодействия с базами данных 29
Заключение 31
Список литературы 32
Поддержание программного кода в приличном состоянии зачастую является непростой задачей. Безусловно, существуют различные про¬цедуры и техники для этого, начиная от руководств стиля (style guide), которым должны следовать разработчики, заканчивая статическими анализаторами и строгой инспекцией кода (code review).
В данной работе нас интересует класс приложений, в которых ис-пользуются реляционные базы данных. Не у каждого программиста есть отчётливое представление о работе с системами управления база¬ми данных. Тестируя программный код на небольших объёмах данных, разработчик может получить впечатление, что работа с СУБД практи¬чески не отличается от работы с коллекцией объектов в оперативной памяти. Широко используемая парадигма объектно-ориентированного программирования и различные Object Relational Mapping-библиотеки хорошо вписываются в теорию «идеального» кода, но на практике, на реальных объёмах данных, такое слепое следование общепризнанным концепциям программирования может создать значительные пробле¬мы с производительностью, что можно видеть в работах [1] и [2]. Мы хотим проектировать приложения так, чтобы работа с базами данных была эффективна. Как этого добиться? Об этом и пойдёт речь далее.
Рефакторинг - неотъемлемая часть культуры программирования, и подразумевает как рутинные задачи, так и сложную интеллектуальную аналитическую работу. Многие разработчики ищут золотую середину между идеальным кодом и «техническим долгом». Таким образом, тема автоматического рефакторинга набирает всё большую популярность в виду роста объёма исходного кода приложений.
Мы задались вопросом, можно ли каким-то способом повысить эф-фективность взаимодействия с БД, не переписывая приложение «с ну¬ля». Различные среды разработки, такие как IDEA и Eclipse предлага¬ют мощные инструменты для рефакторинга кода, но они не касаются анализа и оптимизации фрагментов кода, содержащих SQL-запросы. В виду отсутствия подобных решений, было решено исследовать возмож¬ность анализа и автоматического рефакторинга вычислительно неэф¬фективных фрагментов программного кода.
В связи с тем, что наша цель - повысить эффективность приложе¬ния за счёт улучшения взаимодействия с БД, в нашей работе рассмат¬риваются следующие задачи:
• Определить и уметь находить вычислительно неэффективные фраг-менты кода;
• На основе статического и динамического анализа выдавать советы по улучшению исходного кода;
• Производить трансформацию (рефакторинг) в автоматическом ре¬жиме;
Что касается первой подзадачи, то было решено начать с простых вещей, например, однотипных запросов в цикле, постепенно переходя к анализу более сложных случаев. При решении второй подзадачи под динамическим анализом подразумевается замеры времени выполнения методов и общего времени выполнения приложения, а также построе¬ние и простейший анализ «графа вызовов». Третья подзадача являет¬ся не только самой сложной по реализации, но и самой важной. Для её реализации было решено использовать open-source библиотеку Java Parser [9], которая переводит исходный код приложения в абстрактное синтаксическое дерево.
Для решения задач, были выбраны следующие технологии: драй¬вер JDBC и СУБД Oracle 11G. Версия Java не так принципиальна на данном этапе нашего исследования, но использовался JDK версии 1.8.
На основе анализа проблемы для ряда простых шаблонов намечен¬ные задачи были решены. Благодаря open-source инструментам, мы смогли анализировать исходный код Java-приложений как абстрактное синтаксическое дерево, а также вносить необходимые изменения в него. Была исследована и реализована возможность выделения предопреде-лённых вычислительно неэффективых фрагментов программного кода, касающиеся выполнения SQL-запросов в цикле. Исходя из выделенных «проблемных» шаблонов, мы смогли выдавать советы по улучшению программного кода (запись в лог-файл). Были приведены и импле-ментированы алгоритмы по поиску и автоматической трансформации найденных неэффективынх фрагментов. Для оценки полезности и эф-фективности выполненных посредством трансформации изменений мы использовали комплекс из различных оценок, таких как цикломатиче- ская сложность и замеры времени выполнения фрагмента кода (при¬ложения). Для проверки эквивалентности произведённых изменений - использовали JUnit-тесты.
Как показали эксперименты, после произведённых трансформаций ранее наблюдаемый линейный рост времени выполнения «проблемных» фрагментов кода практически сводится к постоянной.
В будущем целесообразно рассмотреть более общие и сложные шаб¬лоны, зависящие от конкретных требований к коду анализируемого приложения.