В поиск Яндекса приходит множество разнородных запросов. Кроме задачи «найти конкретный сайт» пользователи спрашивают про погоду, спор-тивные матчи, места, людей, товары, события, животных и многое другое.
Ссылки на сайты, которые отображаются на главной странице, назы¬ваются органической выдачей. В то время как блоки, помогающие решить пользователю более специфичные задачи (погода, спортивные матчи, поиск билетов и тому подобное), называются тематическими блоками или «колдун- щиками».
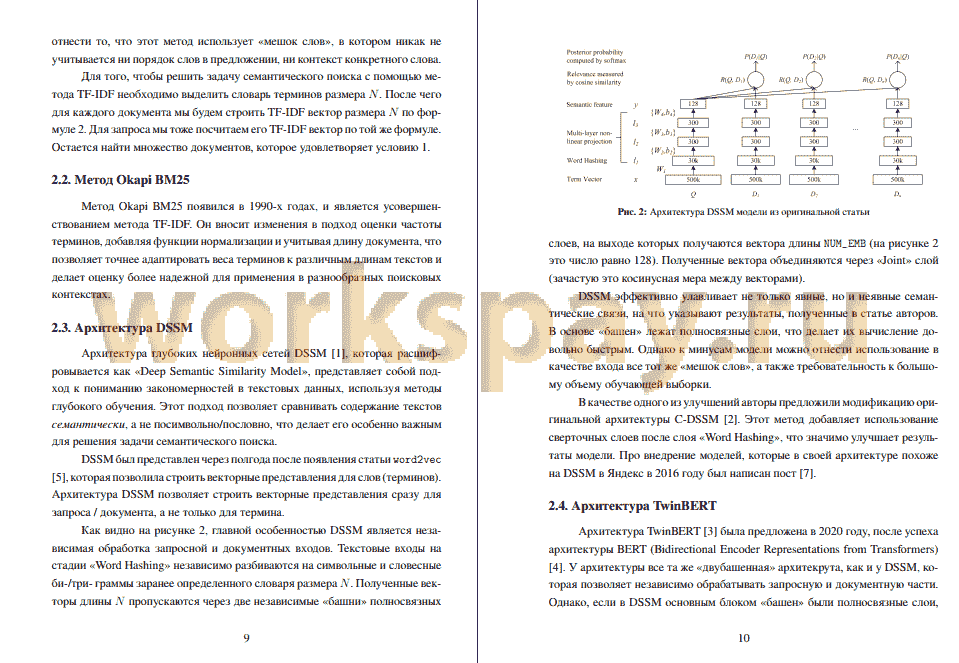
Объектный ответ — это колдунщик, который помогает решить ин- фосценарный запрос пользователя. Инфосценарный запрос - это запрос про какой-то объект, событие, животное и тому подобное, про то что можно вы-делить в какой-то объект и дать краткую сводку о нем.
Объектный ответ собирается автоматически на основании пользова-тельских запросов, а также различных источников информации: Википедия, Викимедиа, Кинопоиск, и другие. Работа объектного ответа состоит из двух этапов:
• Сборка объектной базы - агрегирование информации об одном и том же объекте в один документ (также именуемый карточкой).
• Рантайм (контур срабатываний) - выбор карточки объектного ответа из базы для конкретного пользовательского запроса.
Процесс сборки базы - оффлайн процесс, который занимает длительное время. В результате построения базы собираются сотни миллионов докумен¬тов. Контур срабатываний объектного ответа имеет ограничение на время исполнения в 130мс, что накладывает ограничение на методы, используемые для поиска документов в базе.
Одной из компонент контура срабатываний является полнотекстовый поиск на базе инвертированного индекса, с последующей фильтрацией документов. Для фильтрации документов используются формулы catboost.
Предложенная схема обучения, а также архитектура модели машинного обучения для задачи семантического поиска позволяет в короткие сроки, без внедрения новых архитектур и написания дополнительного кода для их интеграции, получить преимущество относительно классической DSSM архитектуры.
В работе также проанализировано влияние качества входных данных для обучения моделей. Было выявлено, что тексты на разных языках, а также балансировка данных по значению целевой вещественной переменной оказывают положительное влияение на качество работы модели.
Хотя в данной работе и не был рассмотрен подход, при котором DSSM эмбеддинги для запросной части, и TwinBERT эмбеддинги для документной части обучаются совместно (соединяясь архитектурно), экспериментам над такой архитектурой уже положено начало.
Одна из версий моделей (DSSM, дистиллированная из оценок BERT модели) уже интегрирована в контур срабатываний объектного ответа. Это принесло рост релевантных показов объектного ответа на выдаче Яндекса в размере +0.69% от суточных показов. Это статистически значимое изменение, с p-value = 3.12e — 9. Лучшая модель DSSM эмбеддингов, которые дистиллированы из TwinBERT эмбеддингов, на данный момент проходит оф-флайн тестирование.