Тема: Глубокое обучение с подкреплением в высокочастотном трейдинге
Закажите новую по вашим требованиям
Представленный материал является образцом учебного исследования, примером структуры и содержания учебного исследования по заявленной теме. Размещён исключительно в информационных и ознакомительных целях.
Workspay.ru оказывает информационные услуги по сбору, обработке и структурированию материалов в соответствии с требованиями заказчика.
Размещение материала не означает публикацию произведения впервые и не предполагает передачу исключительных авторских прав третьим лицам.
Материал не предназначен для дословной сдачи в образовательные организации и требует самостоятельной переработки с соблюдением законодательства Российской Федерации об авторском праве и принципов академической добросовестности.
Авторские права на исходные материалы принадлежат их законным правообладателям. В случае возникновения вопросов, связанных с размещённым материалом, просим направить обращение через форму обратной связи.
📋 Содержание
1. ОБЗОР ЛИТЕРАТУРЫ 7
1.1 Алгоритмы глубокого обучения с подкреплением 7
1.1.1 Trust Region Policy Optimization (TRPO) 7
1.1.2 Proximal Policy Optimization (PPO) 8
1.1.3 Asynchronous Advantage Actor-Critic (A3C) 8
1.1.4 Deep Deterministic Policy Gradient (DDPG) 8
1.1.5 Twin Delayed DDPG (TD3) 8
1.1.6 Soft Actor-Critic (SAC) 9
1.2 Применение Ape-X для обучения агента 10
2. МЕТОДЫ 12
2.1 Формализация задачи в терминах обучения с подкреплением 12
2.1.1 Базовая постановка задачи 12
2.1.2 Улучшения среды 12
2.1.3 Разработка признаков 13
2.2 Варианты архитектуры 17
2.2.1 Полносвязные нейронные сети 18
2.2.2 Сверточные нейронные сети 18
2.2.3 Сети долгой краткосрочной памяти 19
2.2.4 Общий кодировщик признаков 19
3 . ЭКСПЕРИМЕНТЫ 20
3.1 Сравнение архитектур 20
3.2 Проверка общего кодировщика признаков 20
3.3 Сравнение различных настроек окружения 21
ЗАКЛЮЧЕНИЕ 22
СПИСОК ЛИТЕРАТУРЫ 24
📖 Введение
В контексте высокочастотной торговли, компания «Спектральные технологии», будучи одним из ключевых участников данного сектора, стремится максимизировать свою прибыль и снизить риски, связанные с торговыми операциями. В настоящее время их торговый алгоритм работает на основе заранее фиксированных параметров, которые определяются перед началом торговли и остаются неизменными в течение сессии. Однако, если бы эти параметры могли быть динамически оптимизированы в процессе торговли, компания «Спектральные технологии» могла бы достичь ещё более высоких результатов.
Именно здесь вступает в игру глубокое обучение с подкреплением, один из ключевых подходов в области машинного обучения. Глубокое обучение с подкреплением предоставляет возможность разработки алгоритмов, которые способны обучаться на основе опыта и взаимодействия с окружающей средой. Этот подход позволяет автоматически оптимизировать параметры торгового алгоритма на основе полученных наград и обратной связи от рынка в режиме реального времени. Внедрение глубокого обучения с подкреплением в сферу высокочастотной торговли может принести значительные преимущества, такие как повышение эффективности торговых стратегий, адаптация к изменяющимся рыночным условиям и снижение воздействия человеческого фактора на процесс принятия решений.
Целью данной дипломной работы является создание практического применения глубокого обучения с подкреплением для оптимизации параметров торгового алгоритма компании «Спектральные технологии» в контексте высокочастотной торговли. Мы стремимся разработать инновационный подход, который позволит автоматически оптимизировать параметры торгового алгоритма на основе полученного опыта и обратной связи от рынка в режиме реального времени...
✅ Заключение
В ходе работы мы:
• Сравнили различные алгоритмы DRL. Лучше всего для нашей задачи подошел алгоритм SAC. Его мы реализовали и использовали для обучения агента при проведении экспериментов.
• Разработали эффективный пайплайн обучения агента на основе Ape-X. В нем данные собираются асинхронно несколькими агентами-исследователями, а полученный опыт эффективно переиспользуется с помощью буфера опыта с приоритезацией.
• Определили среду в формальной постановке RL задачи и смогли с помощью нормализации наград, буферизации наблюдений и вручную сконструированных признаков заставить ее работать с нейронными сетями.
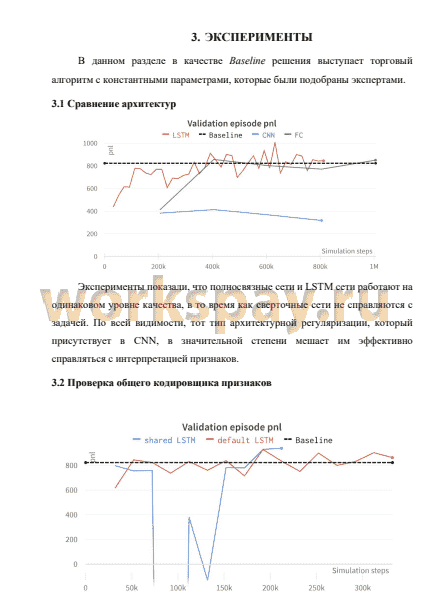
• Сравнили различные варианты архитектуры нейронных сетей в обучении агента. Выяснили, что сверточные сети не подходят для решения поставленной задачи, в то время как полносвязные и LSTM сети достигают желаемого качества.
• Выяснили, что использование общего кодировщика для актора и критиков алгоритма SAC не улучшает результатов, а наоборот делает процесс обучения менее стабильным.
Мы успешно достигли поставленных в рамках нашего исследования задач. Обученный агент показывает качество работы сравнимое с качеством работы торгового алгоритма, настроенного экспертами. Однако, несмотря на эти достижения, нельзя сказать, что показатели значительно улучшились по 22
сравнению с использованием константных параметров. Есть несколько гипотез о том, как можно улучшить результаты:
1. Подбор более информативных и релевантных для торгового алгоритма признаков.
2. Улучшение качества работы торгового алгоритма упростит задачу для агента. Эксперименты с более современными версиями торгового алгоритма могут показать улучшение результатов по сравнению с константными параметрами.
3. Обучение агента на большем объеме тренировочных данных.
Улучшение качества работы агента может стать темой для последующих исследований в этой области, а данная работа служит хорошей отправной точкой для них.
📕 Список литературы
🖼 Скриншоты