Тема: Методы детектирования дефектов нефтепроводов на основе данных внутритрубной диагностики
Закажите новую по вашим требованиям
Представленный материал является образцом учебного исследования, примером структуры и содержания учебного исследования по заявленной теме. Размещён исключительно в информационных и ознакомительных целях.
Workspay.ru оказывает информационные услуги по сбору, обработке и структурированию материалов в соответствии с требованиями заказчика.
Размещение материала не означает публикацию произведения впервые и не предполагает передачу исключительных авторских прав третьим лицам.
Материал не предназначен для дословной сдачи в образовательные организации и требует самостоятельной переработки с соблюдением законодательства Российской Федерации об авторском праве и принципов академической добросовестности.
Авторские права на исходные материалы принадлежат их законным правообладателям. В случае возникновения вопросов, связанных с размещённым материалом, просим направить обращение через форму обратной связи.
📋 Содержание
Актуальность 4
Практическая значимость работы 5
Постановка задачи 6
Цель работы 6
Задачи работы 6
Обзор литературы 7
Глава 1. Введение в предметную область 11
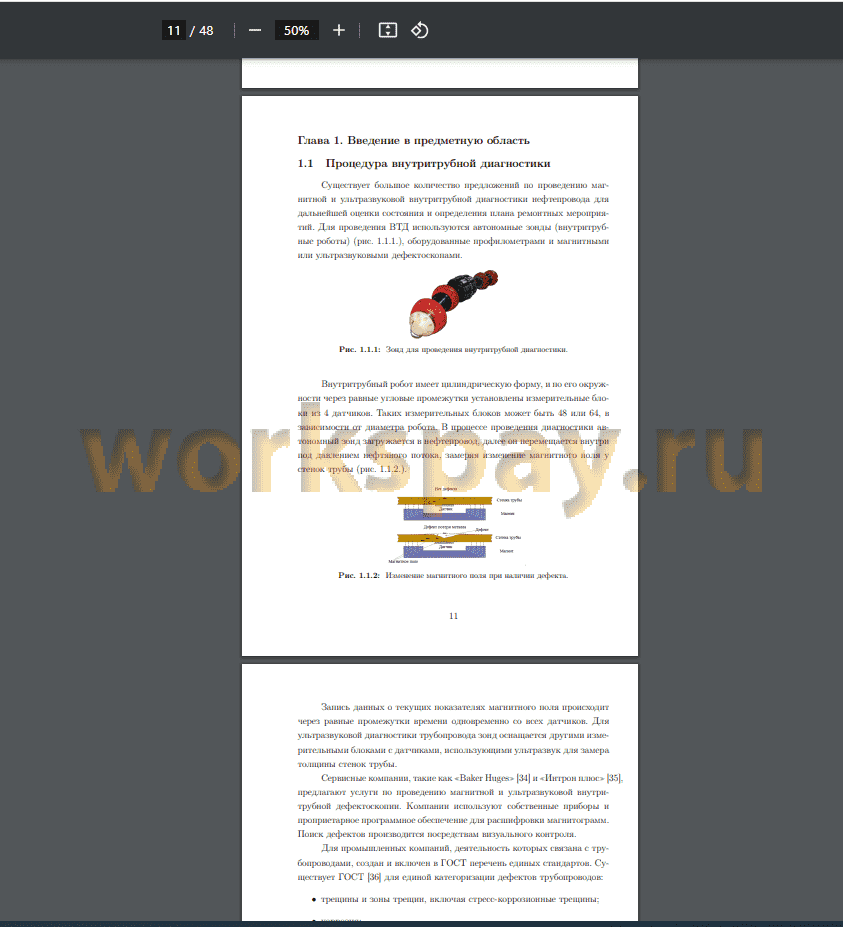
1.1. Процедура внутритрубной диагностики 11
1.2. Методы визуального контроля дефектов 13
Глава 2. Разработка методов детектирования дефектов ... 15
2.1. Структура и особенности данных 15
2.2. Аугментация датасета 21
2.3. Исследование дефектов 22
2.4. Поиск дефектов по паттерну 24
2.5. Детектирование дефектов методами классического машинного обучения 25
2.6. Классификация дефектов методами классического машинного обучения 26
2.7. Классификация дефектов методами на основе нейронных
сетей 27
Глава 3. Проведение оценки качества алгоритмов 32
3.1. Процедура оценки качества 32
3.2. Результаты поиска дефекта по паттерну 32
3.3. Результаты детектирования методами классического машинного обучения 34
3.4. Результаты классификации методами классического машинного обучения 35
3.5. Результаты нейросетевого подхода 37
3.6. Выводы 40
Заключение 41
Результаты работы 41
Перспективы развития 41
Список литературы 43
📖 Введение
Благодаря этому многие области промышленности получили большой толчок в развитии, например, автомобильная промышленность или нефтегазовая промышленность. В качестве примера можно привести то, что за последние годы в группе компаний «Газпром Нефть» были внедрены новейшие решения для оптимизации технологических и производственных процессов [1]:
• Проект «Когнитивный геолог», автоматизирующий предварительную обработку данных, полученных в результате геологоразведочных работ.
• Технология «КиберГРП» применяется для моделирования гидроразрыва пласта.
• Экспертная система «ГгсБА» накапливает информацию и формирует базу знаний по «Большой Ачимовке». На основе различных данных она помогает подобрать оптимальное технологическое решения для бурения новой скважины.
На текущий момент «Газпром Нефть» проводит огромную исследовательскую программу по созданию информационных и технологических решений для проведения геологоразведочных работ и дальнейшей разработки трудноизвлекаемых запасов нефти [2].
Практическая значимость работы
На балансе нефтедобывающей компании находится порядка 12 тыс. км промысловых трубопроводов. Одной из важных задач является оценка состояния эксплуатируемых трубопроводов [3]. На данный момент эта процедура требует большого количества ручного труда высококвалифицированных специалистов при визуальном контроле результатов внутритрубной диагностики (ВТД). Эксперты тратят до одного месяца на интерпретацию данных внутритрубной диагностики одного километра трубы. Автоматизация данного процесса позволит сократить время между проведением ВТД и интерпретацией результатов, а также уменьшить влияние человеческого фактора. В результате уменьшится количество прорывов нефтепроводов и утечек нефти. В компании разрабатывается программный комплекс для детектирования дефектов на основе экспертных правил. Использование методов машинного обучения может повысить качество детектирования дефектов.
Практическая значимость работы заключается в том, что предложенные методы детектирования дефектов позволят повысить качество процесса интерпретации данных ВТД и могут быть внедрены в разрабатываемый программный комплекс.
✅ Заключение
В рамках проделанной работы были выполнены следующие задачи:
• проведен обзор и анализ подходов и методов машинного обучения для детектирования аномалий и дефектов;
• собраны и предобработаны данных внутритрубной диагностики для обучения и оценки качества моделей, написан парсер для расшифровки бинарных файлов, а также проведена аугментация и балансировка датасетов;
• реализованы методы с использованием нейронных сетей и алгоритмов машинного обучения для обнаружения дефектов;
• проведено тестирование и оценка качества разработанных алгоритмов в процессе кроссвалидации на подготовленной выборке;
• полученные результаты проанализированы и сформированы рекомендации по улучшению разработанных подходов в будущем;
• полученное решение интегрировано в программный комплекс для информатизации процесса внутритрубной диагностики;
• получено свидетельство о государственной регистрации программы для ЭВМ [50].
Перспективы развития
На основании проведенных экспериментов для улучшения качества детекции дефектов следует предпринять следующие шаги:
• предложить решение, позволяющее определять состояние магнитограммы;
• исключить из выборки некорректные магнитограммы;
• обогатить выборку хорошими магнитограммами;
• перепроверить текущую разметку магнитограмм с помощью экспертов;
• расширить признаковое описание дефектов на основе работы CNN сетей.
• усложнить архитектуру используемых сетей CNN и добавить Batch Normalization слои;
• рассмотреть возможность использования autoencoders в данной задаче.
📕 Список литературы
🖼 Скриншоты