Тема: Complexity of conjunctive linear LL(k) grammars
Закажите новую по вашим требованиям
Представленный материал является образцом учебного исследования, примером структуры и содержания учебного исследования по заявленной теме. Размещён исключительно в информационных и ознакомительных целях.
Workspay.ru оказывает информационные услуги по сбору, обработке и структурированию материалов в соответствии с требованиями заказчика.
Размещение материала не означает публикацию произведения впервые и не предполагает передачу исключительных авторских прав третьим лицам.
Материал не предназначен для дословной сдачи в образовательные организации и требует самостоятельной переработки с соблюдением законодательства Российской Федерации об авторском праве и принципов академической добросовестности.
Авторские права на исходные материалы принадлежат их законным правообладателям. В случае возникновения вопросов, связанных с размещённым материалом, просим направить обращение через форму обратной связи.
📋 Содержание
1 Introduction 2
2 Definitions 3
3 The aligned form of an LL(k) linear conjunctive grammar 6
4 Transforming an LL(k) linear conjunctive grammar to LL(1) linear conjunctive 11
4.1 Short rules elimination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.2 Reduction to LL(1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5 An efficient parser for aligned LL(1) linear conjunctive grammars 16
6 Parsing in LOGSPACE 21
7 Error-correction in linear conjunctive grammars is not fixed parameter
tractable 21
8 Error correction in an intersection of linear LL(1) grammars with no tailless
rules 25
9 Conclusion 29
📖 Введение
The LL(k) parsing is applicable to a subclass of formal grammars known as the LL(k) grammars; the main theoretical properties of these grammars have been established in the papers of Knuth [11], Lewis and Stearns [13], and Rosenkrantz and Stearns [22]. In particular, Rosenkrantz and Stearns [22] and Kurki-Suonio [12] proved that, for each k, the LL(k + 1) grammars can define more languages than the LL(k) grammars, leading to a strict hierarchy of LL(k) languages by k.
A natural subclass of LL(k) linear grammars, which obey the LL(k) restriction and allow at most one nonterminal symbol on the right-hand side of any rule, was first studied by Ibarra et al. [8] and by Holzer and Lange [7], who have characterized the computational complexity of the languages defined by these grammars. The language-theoretic properties of linear LL(k) languages were recently investigated by Jiraskova and Klima [10]. Lately, the authors [21] have demonstrated that in the case of LL(k) linear grammars, the hierarchy by k collapses, that is, every language defined by an LL(k) linear grammar for some k can be defined by an LL(1) linear grammar. This transformation incurs an exponential blow-up in the size of the grammar, and, furthermore, it was proved that this blow-up is unavoidable in the worst case [21].
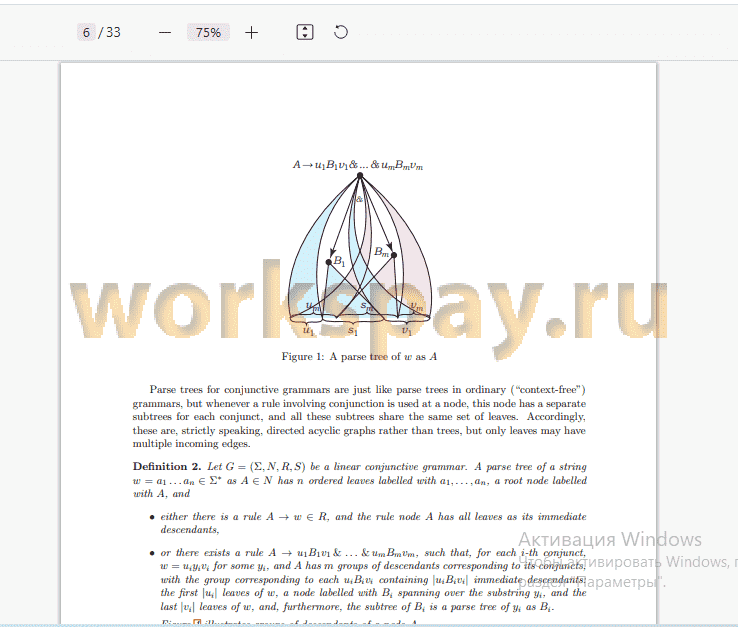
The idea of LL(k) parsing is applicable to several generalizations of ordinary (“context-free”) formal grammars. One of such extensions are conjunctive grammars, introduced by Okhotin [14], which enrich the expressive power of ordinary grammars by allowing a conjunction operation in the rules; a rule A ^ а&в defines all strings that can be represented both as a and as в. The subclass of LL(k) conjunctive grammars and the associated linear-time parsing algorithm were defined [15, 19], but almost nothing is known about its theoretical properties.
This paper investigates LL(k) parsing for a subclass of conjunctive grammars called linear conjunctive grammars, that is, grammars in which every conjunct in every rule may contain at most one nonterminal symbol. Linear conjunctive grammars are important for being equivalent to one-way real-time cellular automata, also known as trellis automata [16, 17], and the associated family of languages has received quite a lot of attention in the literature [4, 6, 9, 23], including some recent work on their expressive power [24, 25]. Turning to the LL(k) subfamily of linear conjunctive grammars, it was proved that they cannot define a language as simple as { anbns | n ^ 0, s G {a, b} } [20], but this is about all that is known about this family. However, in spite of these grammars’ inability to define some particular examples, this family may still contain some computationally hard specimens. Furthermore, it remains unknown whether these languages form a hierarchy by k.
This paper addresses both the computational complexity of LL(k) linear conjunctive grammars, and the existence of a hierarchy by k. First, it is shown that, like for ordinary LL(k) linear grammars, the hierarchy by k collapses, and LL(1) linear conjunctive grammars are as powerful as LL(k) linear conjunctive, for any k. Secondly, a parsing algorithm for LL(k) linear conjunctive grammars is constructed, which not only works in linear time, but also uses logarithmic space. Accordingly, all languages defined by LL(k) linear conjunctive grammars lie in the complexity class L, and therefore, under the standard assumption that L = P, these grammars cannot define any P-complete languages, unlike linear conjunctive grammars without the LL(k) condition [9].
A natural generalization of parsing is error correction. In the error correction problem some language L is fixed and an input string w with an integer k are given, and the task is to determine whether there exists a string w' from L which is in some way close to w. As a measure of “closeness” we will use Hamming distance d, so that the question is whether there exists a string w' G L, such that d(w, w') < k, where k is some preset parameter.
Error correction can be trivially solved by trying to parse each string in the k-neighbourhood of w, which yields the running time Q(|w|k). However, the latter algorithm becomes inapplicable very quickly as the parameter k grows, and hence one is usually interested in error-correction algorithms which work in polynomial time or at least which are fixed parameter tractable with respect to k, i.e. work in time O(f (k) • poly(|w|)) for some computable function f.
Error correction in a language defined by a single non-conjunctive grammar was studied by Aho and Peterson [1] and was proved to admit a polynomial time algorithm. The problems of error correction for more general classes of languages: for languages defined conjunctive grammars or for languages defined by a finite intersection of non-conjunctive grammars, however, were not yet well-addressed, and efficient algorithms for these problems are unknown.
Generally, analysis of an intersection of formal languages is challenging, since the resulting language can be far more complicated than the initial ones, to such an extent that a lot of natural problems, that could be efficiently solved for the initial languages, become uncomputable.
This paper presents some bounds on classes on linear conjunctive languages, for which efficient error correction is possible.
First, for a general case of linear conjunctive grammars, without an LL(k) property, it is shown that, under a standard assumption that WH ^ FPT, error correction is not fixed parameter tractable. This is done by a parameterized reduction of the WCS problem to the problem of correcting k errors in a particular linear conjunctive language.
Secondly, a polynomial time error-correction algorithm for an intersection of grammars from a particular subclass of linear LL(k) family is presented. This class is basically linear LL(1) grammars with an additional property that for each rule A uBv the string v is not shorter than u.
✅ Заключение
Can one obtain even a tighter bound on this class? The parser presented in Section 5 stores a set of stacks, with the number of stacks bounded by the size of the grammar, and each of the computation steps consists of several operations on these stacks. If those operations treated each stack independently of other stacks, it would be possible to represent an LL(k) linear conjunctive language as an intersection of ordinary, non-conjunctive LL(k) linear languages. The question of whether any LL(k) linear conjunctive language can be represented as an intersection of nonconjunctive languages remains unanswered and the author hopes that his results may help contribute to solving this problem.
In contrast to the recognition problem for LL(k) linear conjunctive languages, which was proved to be in L, the error correction problem for this class seems to be significantly harder. Even for a rather toy class of grammars, considered in Section 8 error correction is not trivial, and, as it was shown in Section |7, for a more general case of linear conjunctive languages without the LL condition, an efficient error correction algorithm is unlikely to exist. The results from Sections 7 and 8 can be viewed as an upper and lower bounds for the subclass of linear conjunctive languages which allows efficient error correction. The bounds presented leave huge open space between them unexplored and it is interesting to obtain tighter bounds. That can be done by, on the one hand, providing an error correcting algorithm for a larger subclass of languages and, on the other hand, by proving the fixed parameter intractability for the narrower class of languages.
📕 Список литературы
🖼 Скриншоты